First-hand measurement: OpenAI Deep Research
At 8am this morning, OpenAI released their new product Deep Research
After using it for the first time, I made this review. First, the conclusion: extremely strong, but very unstable

Deep Research is a more advanced agent, found in ChatGPT.
After you give Deep Research a task, such as “How did DeepSeek rise to prominence?”, it will automatically search and analyse a large amount of online information and give you a pretty good report.
It should be noted that it may take up to 10 minutes or even longer to complete the task.
It is interesting to note that this function is based on the o3 model, but this model is not the original one. It has been fine-tuned to meet the needs related to network connection and data analysis, which makes it better at searching and analyzing text, images and PDFs, and it can also constantly reflect and retry.
Next, I will show some of my test cases. Before that, you can watch the official demo video:

My personal guess is that this feature may be an upgrade to the original WebGPT set. At the same time, this release is indeed very valuable:
- o1 brings deep thinking
- R1 first searches briefly, then deep thinking
- Deep Research can be used with o3-mini, allowing the AI to search deeply first, then think deeply
So deep, so searching…
Let’s call this feature DeepSeek.
Just like OpenAI’s usual “advanced features have limits”, DeepSeek DeepResearch is also limited in use:
- Pro users: available today, limited to 100 times per month
- Plus/Team/Enterprise: coming soon, limited to 10 times per month
- Free users: just wait a little longer…
Of course, these restrictions may be changed in the future.
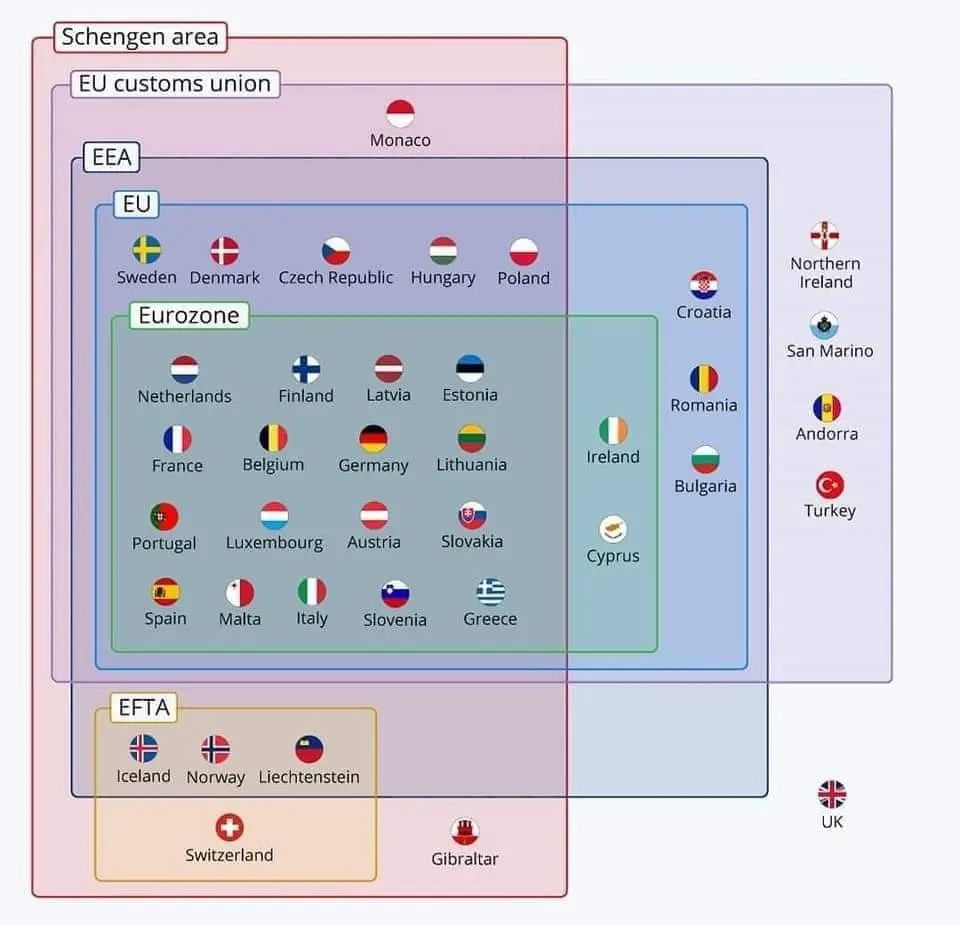
Of course, this feature is also available in different regions. According to the official statement, the following regions are currently unavailable: the United Kingdom, Switzerland, and the European Economic Area (EU + Iceland, Norway, and Liechtenstein)
By the way… I found a classification map online: EU is the European Union and EEA is the European Economic Area
Back to the topic, let’s take a look at Deep Research’s actual measurement, which is supposed to be the first one on the whole network.
Example 1, give him a task goal to execute, a typical Good Case:
Generate an informative business biography to tell the story of how DeepSeek has risen: what happened from the beginning of its establishment to its current popularity.
Here I made a screen recording (10x speed)
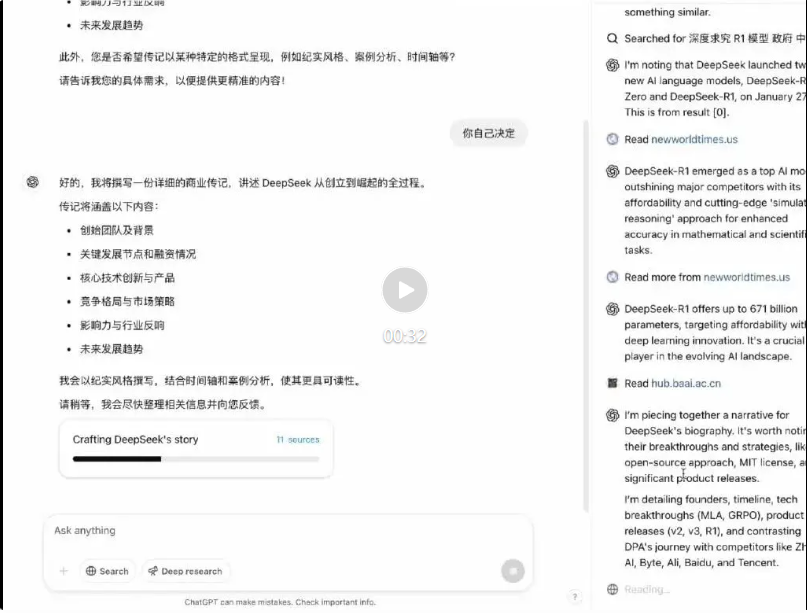
and got this report:

After carefully reading this report… the quality is extremely high.
Of course, there are some minor errors in it, for example, he thinks that “Magic Square Quantization” was established in 2010, but in fact it was established in 2015. But overall, the flaws do not overshadow the merits.
I myself also spent two days writing this before: “DeepSeek’s Growth History: The Technical Expedition of the Light Chaser | Jianghu Record”. You can also compare which version is better.
Example 2: Given a goal and a limited method, this is a typical Bad Case:
I told Deep Research, “I am the manager of the public account ‘Cyber Zen Heart’, and the following is the content data of the public account ‘Cyber Zen Heart’ for January. Please give me some suggestions on content optimization after reading each article.”
Then I attached the following message:
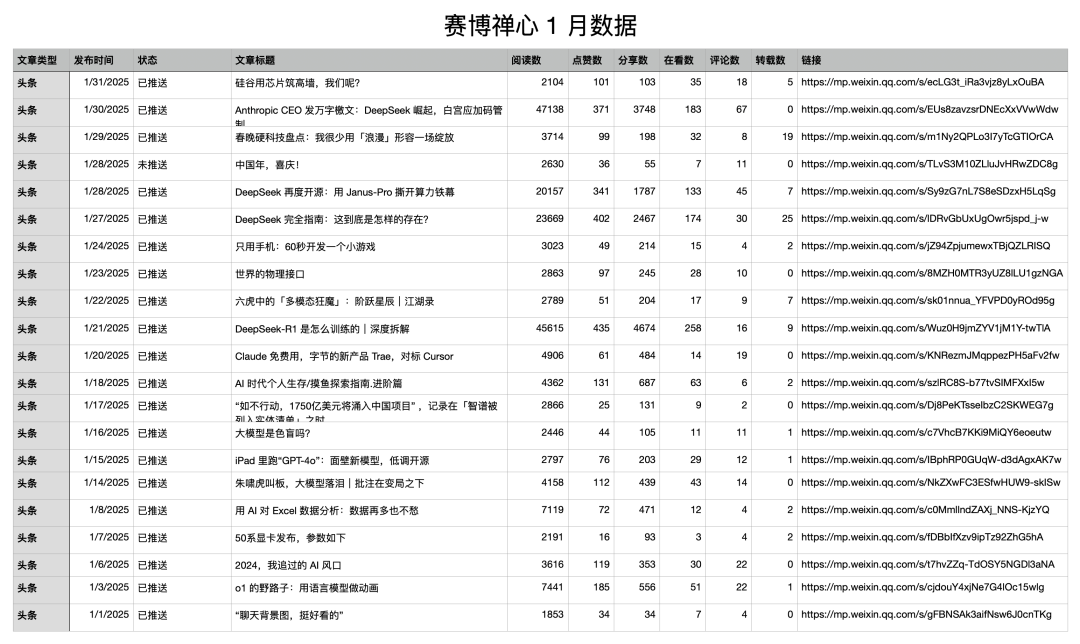
What greeted me was a load of nonsense:

When did I have millions of views… So I reviewed his process and found that it did not follow my instructions to directly access the link, but to search.

After that, I tried it several times, and even when I asked “be sure to visit my link, be sure not to search,” he ignored it. It is not clear why he must search, but from a practical experience point of view, it is most likely from a security perspective that the “user-specified page behavior” is disabled at the system level

Open Research related parameter report
The official Deep Research report also released a related parameter report:
In this report, in addition to OpenAI’s own “far ahead”, I think the two tests mentioned are more interesting:
- Humanity’s Last Exam, HLE
- General AI Assistants, GAIA
Next, I will combine these two tests with the content of OpenAI’s report to analyze Deep Research as a whole.
First is Humanity’s Last Exam: This test contains 3,000 questions, developed by experts from various disciplines around the world, including multiple-choice questions and short answer questions suitable for automatic scoring. Each question has a clear and easily verifiable known solution, but the answer cannot be quickly found by searching the Internet.
Here, I’ll post sample questions from both tests to see if you can answer them (PS: I’m useless, I can’t do it at all):


And in this HLE test, Deep Research achieved an accuracy rate of 26.6%, which is second to none.
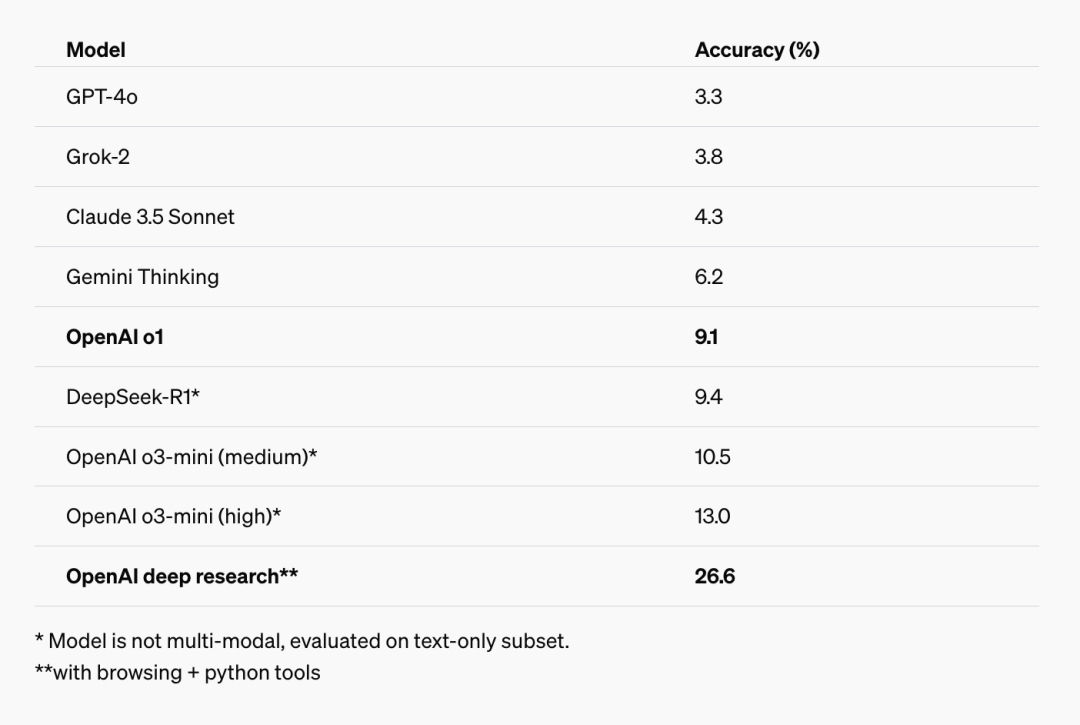
If you are interested in this test, you can find more information here:
The corresponding paper is here:
Another benchmark is GAIA, which is used to evaluate the performance of Agent. It consists of 450 questions with clear answers. The questions are divided into 3 levels, namely Level 1 to 3, with Level 1 being the more basic questions and Level 3 being quite challenging.
Here is a Level 1 question to see how long it takes you to solve it:

And here is a Level 3 question:

In any case, solving these problems requires AI to use a variety of tools, including online searches. If you are interested in this test, you can check the method here:
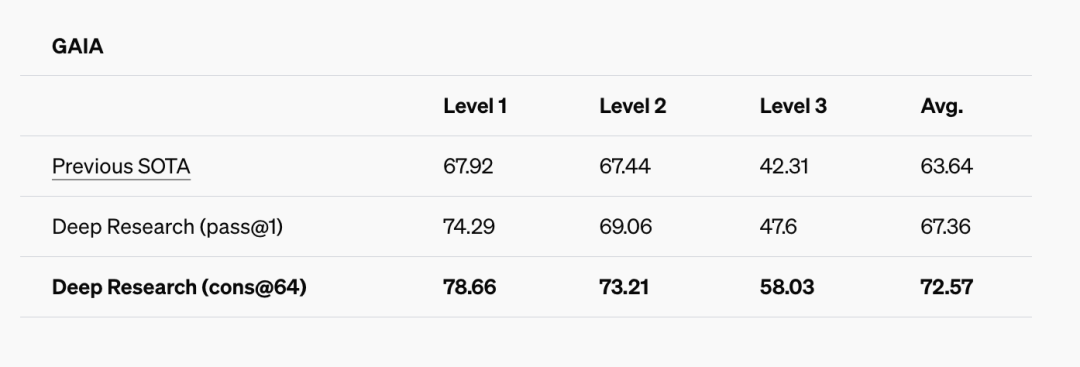
In this test, you will find that Open Research has achieved relatively good results, and has achieved better results than before under the pass@1 and cons@64 standards. Here is some additional information about pass@1 and cons@64:
- pass@1: the probability that an AI will give the correct answer directly on the first try. It can be used to measure whether an AI is directly usable
- cons@64: This is the probability that the correct answer will appear among the 64 answers generated by the AI. It can be used to evaluate the coverage and potential of the AI
But… I still found a flaw. The GAIA Leaderboard access address is on Hugging Face. Here:
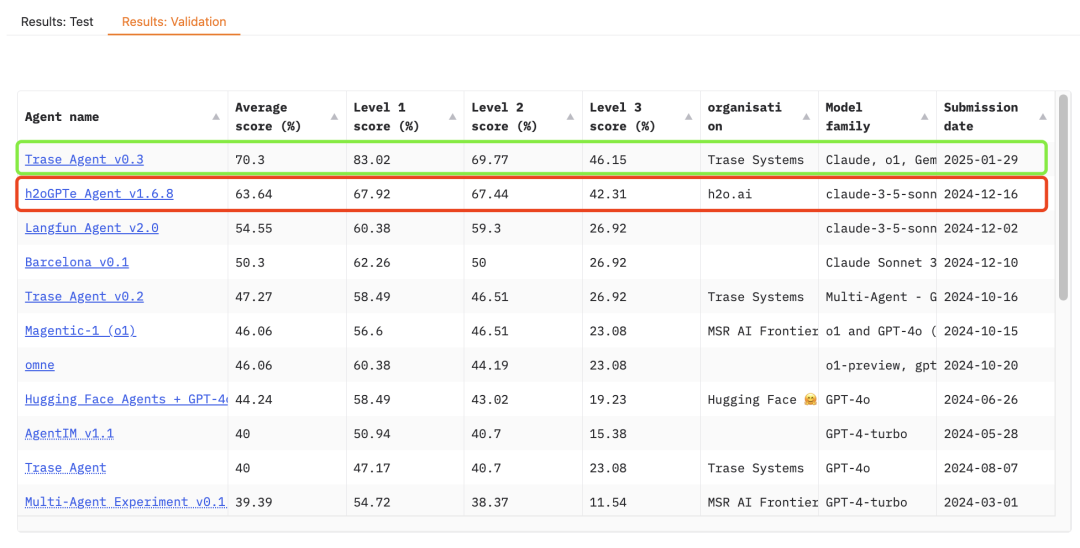
You can see that the “best ever” result published by OpenAI was achieved by h2o, with a record time of 12/16/24. The updated record was released by Trase Systems on January 29 (New Year’s Day). In other words,OpenAI should have been ready for this project before January 29. Haha, it just corresponds to Ultraman’s Twitter:
Example 3: Write a report on OpenAI Deep Research
For “Example 3”, ahhhhhh, I hope to use Deep Research to “write a report on OpenAI Deep Research. Your target audience is AI practitioners, investors and related researchers.”
Five minutes later, I got this report:

Everyone can comment on this report:
- If you think it’s well written, please praise me for being a genius in the comment section;
- If you think it sucks, please insult OpenAI in the comments section
In fact, this is the fourth output from Deep Research. In the first three times, its output was “nonsense and off the mark”.

In the fourth time, I reworded the prompt, added some background information, and repeated the test twice to get a more satisfactory result. Here is the prompt I used in the fourth time: “Just now, OpenAI released a new feature called ‘Deep Research’. Write an analysis report on ‘OpenAI Deep Research’. Your target audience is AI practitioners, investors, and related researchers.”
From the above examples, it can be seen that this OpenAI release is indeed remarkable and has a high upper limit. However, in actual experience, there are also some problems, including but not limited to:
- Very unstable
- If the task is not described very clearly, there may be a relatively large deviation in its understanding and execution, just like the OpenAI Deep Research report (you don’t have the opportunity to make corrections midway)
- Once the task starts, there is no manual intervention (including early termination)
- unable to read links provided by users (at least not public account links)
- the quota is too low: even Pro users only have 100 quota per month
- …
Regarding the quota issue, the official also said: “All paid users will soon get significantly higher rate limits when we release a faster, more cost-effective version of deep research powered by a smaller model that still provides high quality results.”
Since:
OpenAI has released Deep Research
then:
when will DeepSeek release Open Research?